Lückentexte
In Dialog-SETs (aber nicht nur dort) erweisen sich oftmals Lückentext-Komponenten als sehr sinnvoll. Im folgenden Dialog-Test (auch in den Demos zu finden) wird das gut sichtbar. Nach der ersten korrekten Aussage zum Thema wird eine Frage gestellt, wo eine normale Menü-Auswahl von Bezeichnungen für die einzelnen Erdzeitalter das blosse Wiedererkennen der korrekten Bezeichnung belohnen würde, was sehr viel einfacher ist, als das aktive Erzeugen der Begriffe. Hier ist eine Lückentestkomponente sinnvoller:
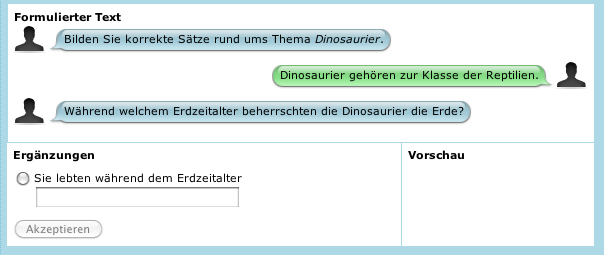
Die Eingaben in Lückentext-Feldern können vom System auf verschiedene Arten ausgewertet werden.
Im einfachsten Fall einer textuellen Eingabe wird auf exakte Übereinstimmung getestet. Um den Lerner aber nicht wegen reiner Rechtschreibfehler abzustrafen, kann vom System eine sprachspezifische Version von fuzzy match verwendet werden, sodass auch leicht inkorrekt geschriebene Wörter erkannt werden. Das System kann dann stillschweigend über den Fehler hinwegsehen (nicht zu empfehlen), den Lerner auf den Fehler aufmerksam machen und weiterfahren, oder dem Lerner die Gelegenheit zur Korrektur geben.
Das letztgenannte Verhalten wird in Abbildung 3 gezeigt.
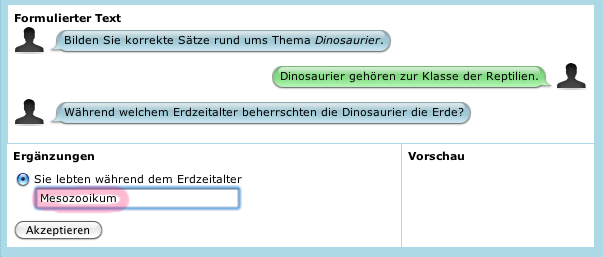
Die Antwort ist nicht ganz korrekt: Es heisst "Mesozoikum". Nach dem Akzeptieren der Eingabe durch den Lerner erscheint daher folgende Reaktion des Systems:
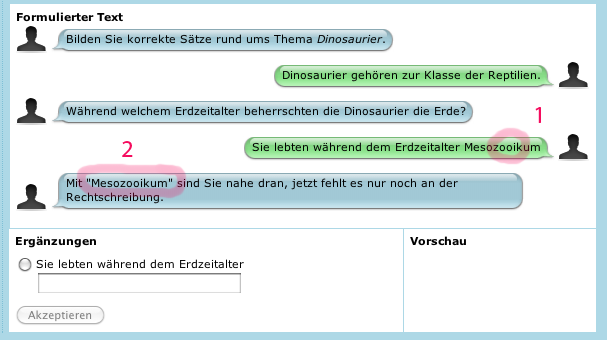
Die inkorrekte Schreibweise "Mesozooikum" (1) wird hier nicht gleich wie ein inhaltlicher Fehler behandelt; dem Lerner wird vielmehr die Gelegenheit gegeben, die Schreibweise zu korrigieren. Natürlich kann man derartige Schreibfehler zusätzlich sanktionieren (mit einem kleinen Punkteabzug), wenn gewünscht.
Ebenfalls zu sehen ist, wie das System eine beliebige Benutzereingabe (hier also die fehlerhafte Schreibweise "Mesozooikum") an eine Variable binden kann, um sie später selbst weiter zu verwenden (2). Eine weitere gezielte Lockerung der Bedingungen für die Korrektheit einer textuellen Benutzereingabe kann durch die Festlegung erreicht werden, dass die Benutzereingabe mit einem gewünschten String beginnen oder enden soll oder ihn irgendwo enthalten soll (je nach Wunsch kann auch von Gross-/Kleinschreibung abstrahiert werden). Dann kann also die Benutzereingabe z.B. daraufhin getestet werden, ob sie mit "Vor" beginnt und mit "ung" endet und irgendwo "eit" enthält, sodass "Vorbereitung" und "Vorverarbeitung" als richtig erkannt würden, „Vorbereiten“ hingegen als falsch (aber „Vorzugsvereiterung“ würde natürlich auch als richtig erkannt).
Noch weiter kann man gehen, indem man die Bedingungen für die Korrektheit einer textuellen Benutzereingabe durch die Festlegung regulärer Ausdrücke beschreibt. Das Muster .*br.*ch*lic wird dann „zerbrechlich“ ebenso wie "unverbrüchlich" und "gebrechlich" erkennen (aber auch "xyzbrichlich").
Bei einer numerischen Eingabe kann man neben einem exakten Zahlwert auch Bedingungen über Minimal- und Maximalwerte definieren.